 Sistemas que são baseados em Machine Learning possuem a capacidade de aprender e evoluir de maneira autônoma à medida que novos dados são introduzidos – isso sem a necessidade explícita de programar. Esta, é uma habilidade maravilhosa que permite criar soluções completamente inovadoras, muitas vezes decisivas para o sucesso de produtos e talvez até mesmo de empresas.
Sistemas que são baseados em Machine Learning possuem a capacidade de aprender e evoluir de maneira autônoma à medida que novos dados são introduzidos – isso sem a necessidade explícita de programar. Esta, é uma habilidade maravilhosa que permite criar soluções completamente inovadoras, muitas vezes decisivas para o sucesso de produtos e talvez até mesmo de empresas.
A pergunta é como Machine Learning de fato entrega essa capacidade? O que acontece nos bastidores?
Neste artigo eu vou apresentar um processo simples, já considerado um padrão mínimo no desenvolvimento de Machine Learning, que vai facilitar seu aprendizado de como as coisas acontecem e, ao mesmo tempo apresentar a você um passo a passo que poderá usar em seus projetos.
“A capacidade de uma organização de aprender, e traduzir esse aprendizado em ação rapidamente, é a vantagem competitiva final.” – Jack Welch, ex-CEO da GE.
Cerveja e Machine Learning
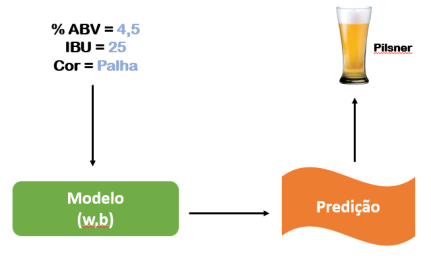
Vamos imaginar que nosso objetivo é construir um sistema que seja capaz de, a partir de uma informação de entrada sobre cerveja, por exemplo o índice do teor de amargor (IBU), o percentual alcoólico (% ABV) e a cor, ele possa responder qual o estilo mais provável daquela cerveja, por exemplo Pale Ale, Lager, Pilsner, etc… Parece interessante não.

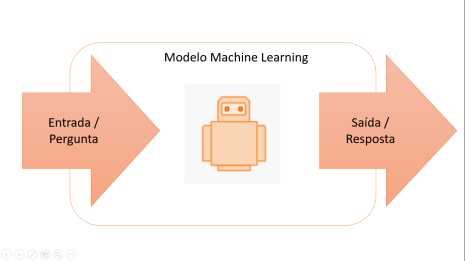
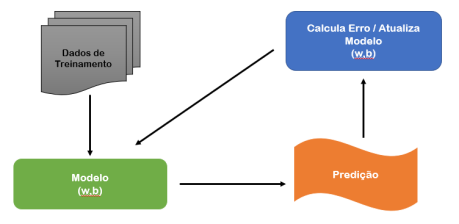
Do ponto de vista de um programa de computador estamos falando da criação de um sistema chamado de modelo, que na verdade é um algoritmo que passa por um processo chamado treinamento. O objetivo final do treinamento é construir o modelo mais acurado possível, isso significa dizer que o modelo deve ser capaz de receber uma entrada ou uma pergunta e devolver uma resposta ou saída correta na maioria das vezes.
Mestres Cervejeiros – Coletando Dados
Uma das primeiras coisas que precisamos fazer quando rodamos um processo de Machine Learning é coletar ou mesmo produzir os dados. Eles serão usados mais tarde para realizar o treinamento do modelo. Nosso projeto é criar um modelo que seja capaz de distinguir entre vários estilos cerveja, precisamos então coletar exatamente os dados que mostram isto.
No dia a dia dos negócios provavelmente os dados de treinamento já estão disponíveis de alguma maneira e o seu o desafio é reconhece-los, extrai-los, transforma-los se necessário e então deixá-los prontos para o treinamento.
De volta as cervejas, existem dezenas de estilos, o que precisamos é de uma tabela com um conjunto bem definido de características onde conseguimos identificar e relacionar cada estilo de cerveja com suas respectivas características.

Uma boa referência para não perdemos muito tempo é a tabela periódica de cervejas. Para manter as coisas simples nossa tabela terá apenas três características: O percentual alcoólico (%ABV), o índice de amargor (IBU), a cor e por último o estilo mais provável que estes dados representam.
| %ABV | IBU | Cor | Estilo |
| 4,5 | 20 | Ambar Profundo | Pale Ale |
| 7,0 | 25 | Ouro | Belgian Ale |
| 3,0 | 20 | Ambar | English Bitter |
| 2,8 | 9 | Ambar | Scottish Ale |
| 2,5 | 19 | Cobre | Brown Ale |
| 3,2 | 30 | Preto | Stout |
| 4,6 | 25 | Palha | Pilsner |
| 2,9 | 8 | Palha | American Lager |
| 4,5 | 18 | Amarelo | European Lager |
| 6,0 | 20 | Ouro | Bock |
Uma vez que terminamos nossa coleta e possuímos informações sobre os diversos estilos de cerveja podemos dizer que temos os dados de treinamento do modelo. Importante entender que tanto a qualidade quanto a quantidade destes dados são cruciais e determinam quão boa e acurada será a predição ou a saída do modelo
Antes de seguirmos para o próximo passo do processo quero reforçar que além das características de cada estilo de cerveja nossa tabela também possui o estilo correspondente, esta informação será fundamental mais à frente no processo de aprendizado e treinamento porque ela representa a resposta correta para cada conjunto de características.
Preparação dos dados
Agora com o conjunto de dados pronto e disponível precisamos prepara-los para ser usado no nosso modelo de identificação de estilos de cervejas. Uma dica interessante é que a ordem dos dados não importa, a explicação disto é simples, usaremos todo o conjunto então, mais cedo ou mais tarde, em algum momento da rotina de treinamento todos os dados participarão e contribuirão para o aprendizado do modelo.
Opcionalmente, a preparação começa com uma boa análise visual dos dados. Interessante plotar os dados de diversas maneiras para verificar algum relacionamento relevante entre as diversas variáveis ou colunas de nossa tabela.
Em alguns momentos os relacionamentos entre dados podem indicar por exemplo que você não precisa de um deles sem perder acurácia das respostas do modelo.
Outra possibilidade é analisar o balanceamento dos dados, as vezes o conjunto de dados pode conter mais informação sobre um estilo de cerveja especifico e muito pouco sobre outro fazendo com que o modelo treinando seja de certa maneira tendencioso e, diminuindo a acuracidade nas respostas. Por exemplo, o modelo pode responder muitas vezes estilos de cerveja que sejam classificados com um estilo parecido ou próximo, mas ainda assim errado.
Às vezes, os dados que coletamos precisam de outras formas de ajustes e manipulação. Existem várias técnicas que podem ser aplicadas nesta fase, coisas como eliminação de erros, retirar repetições, normalização de valores, entre outras.
Para nosso projeto iremos apenas substituir a descrição da cor pelo valor numérico correspondente na escala de cores de estilos de cervejas. Devemos fazer o mesmo para o estilo da cerveja, afinal modelo precisam ser necessariamente treinados por valores numéricos. Para o resto dos dados continuam da mesma forma mantendo a simplicidade.

Escolhendo o modelo
Continuando em nosso “típico” processo de machine learning nosso passo agora é a escolha de qual algoritmo do modelo melhor se encaixa para resolver o problema que desejamos resolver.

Existem dezenas de opções, cada algoritmo tem um objetivo especifico e possui vantagens e desvantagens. Existem aqueles ideais para tratamento de imagens, detecção de objetos, reconhecimento facial, outros muito bons para trabalhar com sequências de dados, como por exemplo interpretação ou tradução textos ou mesmo reconhecer falas humanas através de arquivos de som.
Também temos modelos que são ótimos para predição de informação, tanto valores numéricos como como classes ou grupos e é exatamente este tipo que iremos escolher para nosso projeto. Nós usaremos um modelo de regressão linear
que será treinado pelo conjunto de dados já preparado anteriormente e, quando questionado será capaz, com certo grau de acuracidade, predizer qual o estilo de cerveja de que estamos falando.
Treinamento do Modelo
Este é sem dúvida é o passo mais importante do processo. É aqui que iremos usar nosso conjunto de dados para ensinar o modelo. Cada linha da tabela incrementa e aumenta a capacidade de predição do modelo deixando-o gradativamente mais preciso e acurado. Esta é a razão pela qual a qualidade e quantidade dos dados de treinamento fazem toda a diferença na acuracidades das predições.
Como colocado anteriormente para nosso modelo de predição de estilos de cerveja usaremos um modelo de regressão linear.

Algoritmos de regressão linear são normalmente usados para estimar valores. Eles ajudam a modelar os relacionamentos entre variáveis e podem quantificar a força destas correlações. Além disso, regressões são úteis também para prever ou predizer valores futuros com base em dados históricos. Analisando a fórmula temos:
- X representa as colunas do conjunto de dados menos o estilo
- w representa os pesos de cada coluna
- b representa a inclinação, tendência ou viés do modelo
- Y representa o estilo da cerveja correspondente ao conjunto de dados
Resumindo, X e nossa entrada e Y a saída correta correspondente a cada X. Os valores w e b serão ajustados durante o processo de treinamento para garantir a melhor acuracidade possível do modelo.
Como cada coluna no nosso conjunto de dados representa uma variável de entrada então na verdade X não é apenas um único valor e sim uma matriz de valores. Uma vez que cada X possui seu próprio peso (w), podemos dizer que este também é uma matriz. Então temos uma adaptação da fórmula para trabalhar com múltiplos valores.
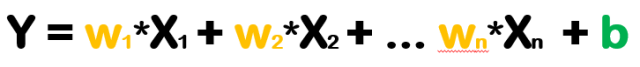
O processo de treinamento em si é simples, envolve a inicialização de valores aleatórios para w e b e, para cada linha do conjunto de dados, utilizamos a entrada (X), executamos a formula e comparamos o resultado com a saída esperada (Y), o erro ou a diferença usamos para ajustar os valores de w e b. Repetimos este processo para todas as linhas do conjunto de dados e ao final temos um modelo treinado capaz de predizer, por exemplo estilo de uma cerveja, a partir de uma entrada específica.
Avaliação dos resultados
Quando o treinamento estiver concluído, é hora de ver se o modelo é bom. A avaliação é o ato de testar o modelo com dados que nunca foram usados para treinamento. Isto nos permite avaliar como o modelo reagi em relação a dados não vistos ainda e assim temos uma prévia de como o modelo pode funcionar no mundo real.
Normalmente dividimos nosso conjunto de dados em dois grupos: o primeiro para o treinamento do modelo e o segundo, para avaliação ou teste após o treinamento. Uma boa regra geral para esta divisão é algo como 80/20 ou 70/30. É claro que isso depende do tamanho do conjunto de dados, mas o ponto principal é que você sempre deve deixar dados para testes.
Predição
Basicamente estamos usando Machine Learning para responder perguntas. Predição é o passo onde podemos começar a perguntar. Neste ponto todo o trabalho e o valor de Machine Learning aparece e é percebido. Finalmente, podemos usar nosso modelo para prever qual é o estio de uma cerveja, dada seu teor alcoólico, amargo e coloração.
Resumo
Chegamos aqui capazes de criar um modelo capaz de determinar o estilo de uma cerveja ao invés de usar o julgamento humano. É hora de uma rápida revisão antes de você começar a extrapolar as ideias para resolver outros problemas onde os mesmos princípios se aplicam:
- Coletando dados
- Preparando esses dados
- Escolhendo um modelo
- Treinamento
- Avaliação
- Predição
